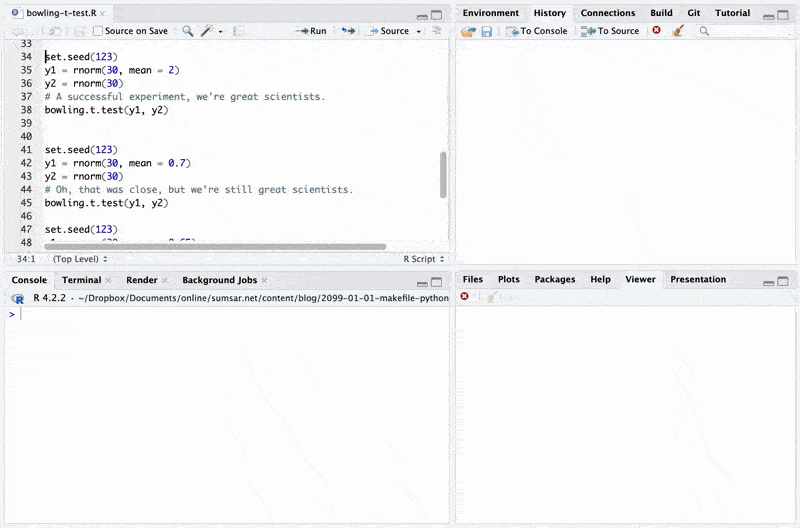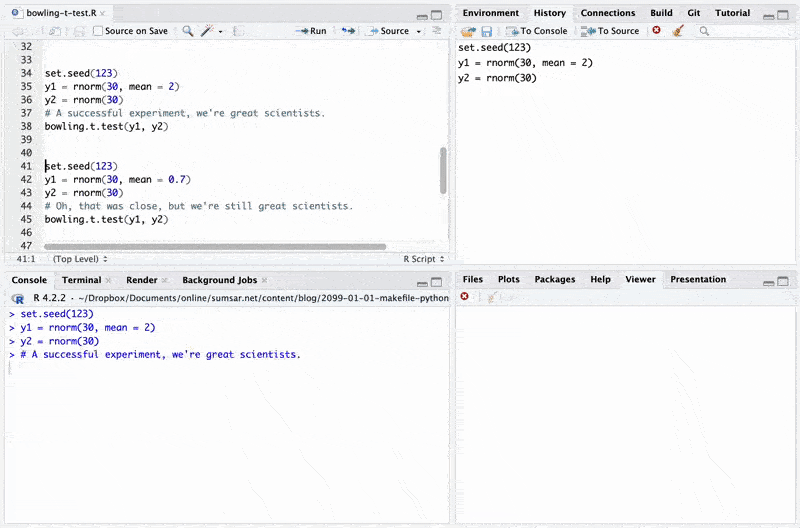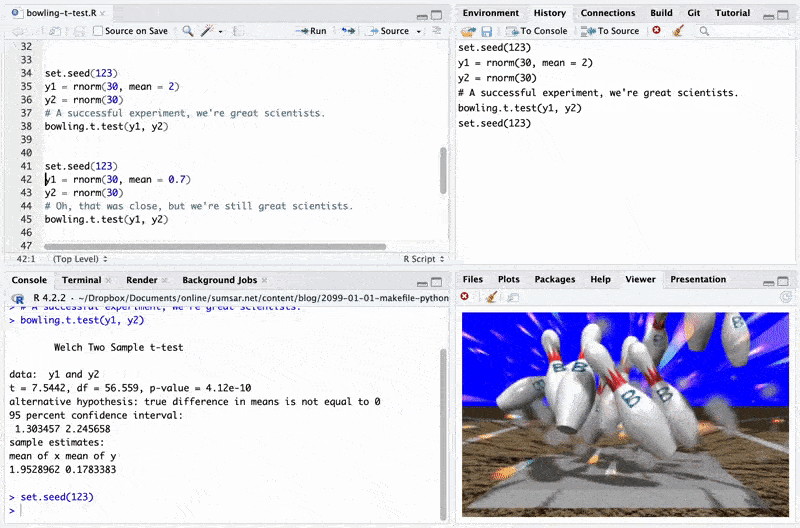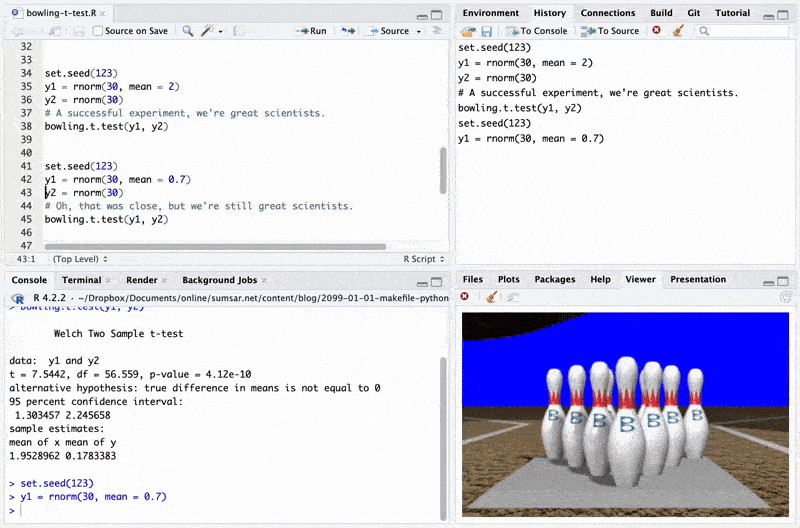
I recently went bowling, and you know those weird 3D-animated bowling animations that all bowling alleys seemed to show whenever you made a strike? They are still alive and well! (At least at my local bowling place). And then I thought: Can I get animations like that into my daily data science workflow? With
Rstudio’s built-in Viewer tab, I absolutely could! Below you find the code for a much improved t.test function that gives you different animations when you hit a strike ($p < 0.01$), a spare ($p < 0.05$), a “near miss” ($p < 0.1$) and a complete miss ($p > 0.1$).
(If you think this is silly, then I agree. Roughly as silly as using ritualized p-value cutoffs to decide whether an experiment is a “success” or not.)
While Big Data™ might not be a buzzword anymore, data that’s uncomfortably large is not going anywhere. In this 30 min. screencast I go through three strategies you can use to tackle big data in R and Python. I also briefly cover three tools:
duckDB,
Apache Spark, and
SnowflakeDB.
You can say what you want about Twitter, but the way animated GIFs are presented on that platform is pretty nice. It’s not so surprising that they play and loop, as one would expect them to do, but the nice thing is that if you click them, they pause. This tiny change in GIF behavior has resulted in a small cottage industry of GIF games (like
here or
here) and click-the-GIF-and-see-what-you-get animations (like
Mario roulette). Here I’ll go through how I made one of the latter in R with
gganimate showing the top 100 downloaded R packages. But first the actual GIF! Click to pause it and learn more about a popular R-package:
I’ve dug up an old, never published, dataset that I collected back in 2013. This dataset fairly cleanly shows that it’s harder to remember words correctly if you also have to remember the case of the letters. That is, if the shown word is Banana and the subject recalls it as Banana, then it’s correct, but banana is as wrong as if the subject had recalled bapple. It’s not very surprising that it’s harder to correctly remember words when case matters, but the result and the dataset are fairly “clean”: Two groups, simple-to-understand experimental conditions, plenty of participants (200+), the data could even be analyzed with a t-test (but then please look at the confidence interval, and not the p-value!). So maybe a dataset that could be used when teaching statistics, who knows? Well, here it is, released by me to the public domain:
In the rest of this post, I’ll explain what’s in this dataset and how it was collected, and I’ll end with a short example analysis of the data. First up, here’s how the memory task was presented to the participants (click here if you want to try it out yourself):
Bitsy is a wonderfully constrained little game maker for making tiny story-driven game-like experiences. Like, picture a Zelda game, but with a minimal color palette and the only thing you can do is walk around and talk to other characters. Thanks to this simplicity there’s a huge community around Bitsy and
many many Bitsy-made games. Another simple thing is Bitsy’s game file format, which is just plain text. This makes it easy to have Bitsy as a “compilation target” and write programs that create Bitsy games. This is exactly what I’ve done!
Over the summer I put together a simple one-page web app that generates random mazes and code for the Bitsy game maker so that these mazes can be directly copy-n-pasted to Bitsy. Why? Maybe you want to have a maze as part of your game, then this gives you a place to start! Or maybe you just like to play autogenerated maze games. But mostly I was just fascinated with Bitsy and wanted to try something out. You can try out the maze generator
here:
I recently spent a lot of time migrating this blog from being generated by
Octopress (RIP) to
the Hugo static site generator. This was fairly painful. Not because any of these frameworks are bad, but just because I also had to migrate all of Octopress’s quirks and special cases to Hugo (slightly different RSS formats, markdown engines, file name conventions, etc.). So, when migrating to Hugo I had two things in mind:
To go back in time to tell young Rasmus to never jump on the static site generator train and just get a bog-standard WordPress blog.
Lacking a working time machine, to rely on as few Hugo-specific features as possible to make any inevitable future migration less painful.
Specifically, I wanted to write my blog posts in plain markdown only, and not rely on
Hugo shortcodes (a Hugo-specific syntax for generating custom html content in markdown). I also wanted each markdown post and its related resources (images, linked files, etc.) to live together in the same folder and not spread out with posts being in content/blog and images being over in static/images, as is the default. The benefit of a setup like this is that I can write markdown posts in anything (say in
Rstudio, which works great as a markdown editor) without having to change any image paths or add short codes to get it to work in Hugo later. Here I’ll go through the problems that I needed to solve to get to this setup.
After a three year hiatus, the
Bayes@Lund mini-conference was back in 2023, this year arranged by
Dmytro Perepolkin and
Ullrika Sahlin. A day packed with
interesting talks and good discussions, three highlights being the two keynote speakers, Aubrey Clayton (author of
Bernoulli’s Fallacy: Statistical Illogic and the Crisis of Modern Science) and Mine Dogucu (co-author of
Bayes Rules!), and the
priorsense package presented by Noa Kallioinen. This package implements diagnostics showing how influential the prior and likelihood is in a Bayesian model telling you, for example, that what you thought was an uninformative prior isn’t that uninformative, at all.
I also presented the short, silly talk: Can AI save us from the perils of P-values? (Spoiler alert… No)
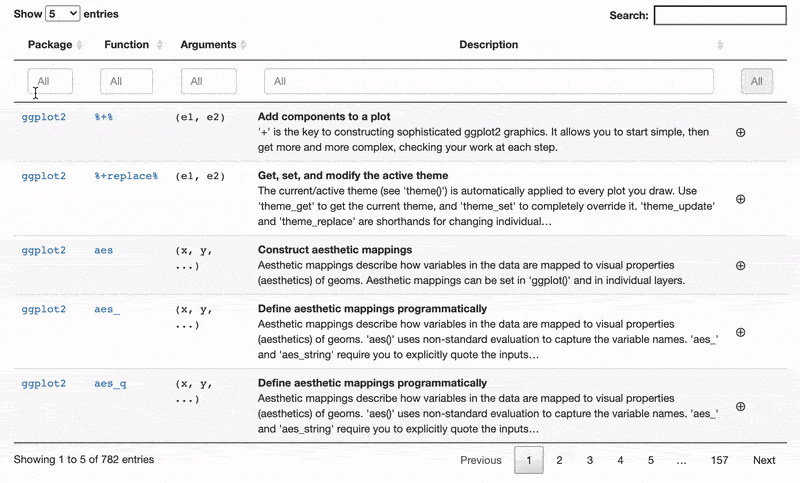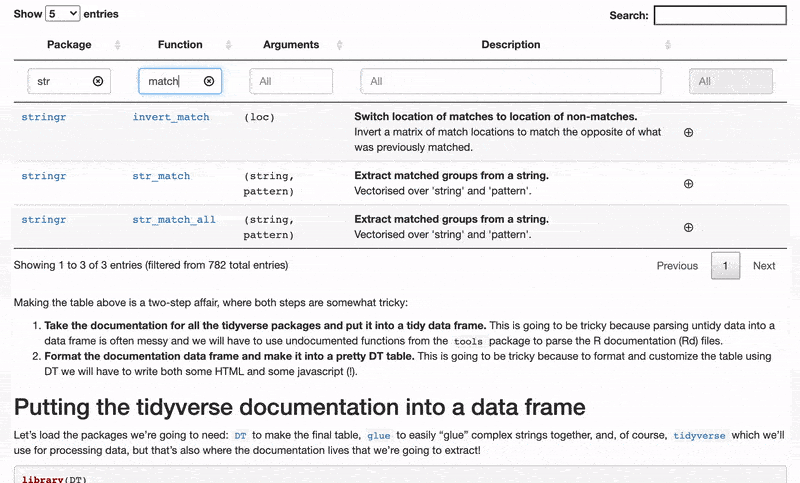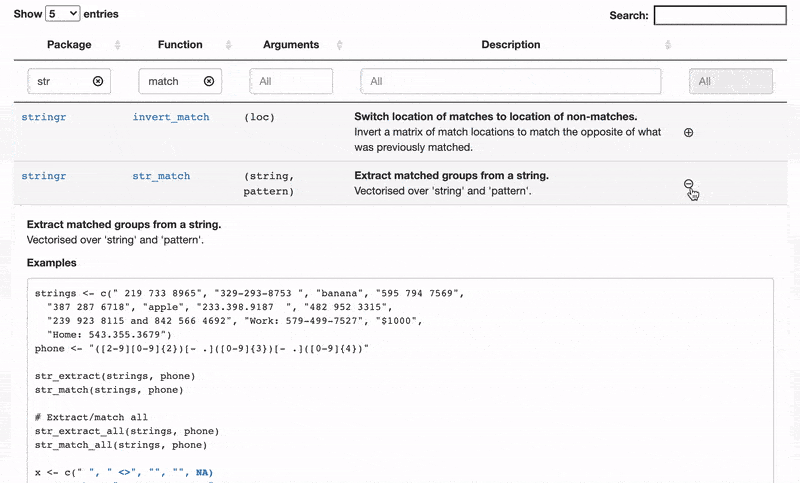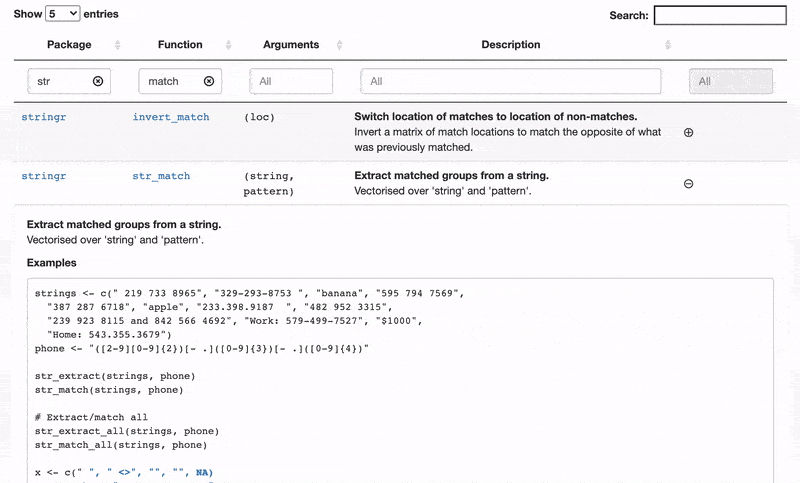
Some tables are beautiful. And yes, I’m talking about the stats-and-numbers kind of tables and not the ones you get at IKEA. Some tables show carefully selected statistics, with headers in bold and spacious yet austere design; the numbers rounded to just the right number of decimal places.
But here we’re not going to make a beautiful table, instead we’re making a useful table. In this tutorial, I’m going show you how to take all the documentation, for all the functions in
the tidyverse core packages, and condense it into one single table. Why is this useful? As we’re going to use the excellent
DT package the result is going to be an interactive table that makes it easy to search, sort, and explore the functions of the tidyverse.
Actually, let’s start with the finished table and then I’ll show you how it’s made. Or a screenshot of it, at least. To read on and to try out the interactive table check out my full submission here.
This January I played the most intriguing computer game I’ve played in ages:
The Return of the Obra Dinn. Except for being a masterpiece of murder-mystery storytelling it also has the most unique art-style as it only uses black and white pixels. To pull this off Obra Dinn makes use of image dithering: the arrangement of pixels of low color resolution to emulate the color shades in between. Since the game was over all too quickly I thought I instead would explore how basic image dithering can be implemented in R. If old school graphics piques your interest, read on! There will be some grainy looking ggplot charts at the end.
The Beta-Binomial model is the “hello world” of Bayesian statistics. That is, it’s the first model you get to run, often before you even know what you are doing. There are many reasons for this:
It only has one parameter, the underlying proportion of success, so it’s easy to visualize and reason about.
It’s easy to come up with a scenario where it can be used, for example: “What is the proportion of patients that will be cured by this drug?”
The model can be computed analytically (no need for any messy MCMC).
It’s relatively easy to come up with an informative prior for the underlying proportion.
Most importantly: It’s fun to see some results before diving into the theory! 😁
That’s why I also introduced the Beta-Binomial model as the first model in my DataCamp course
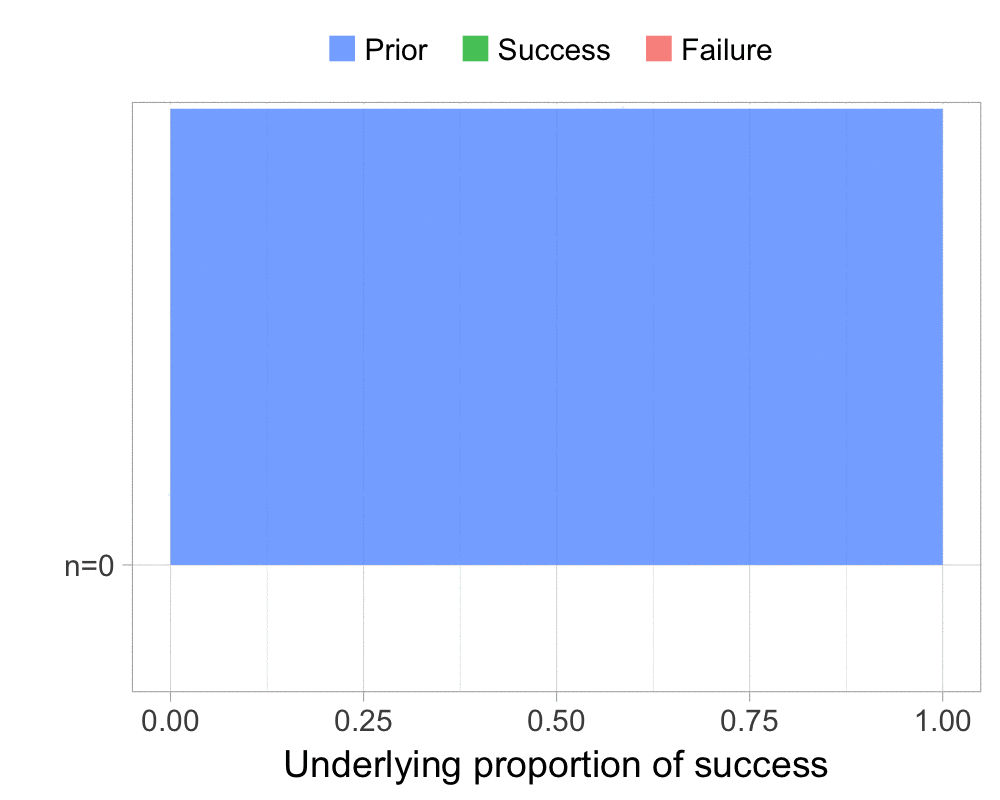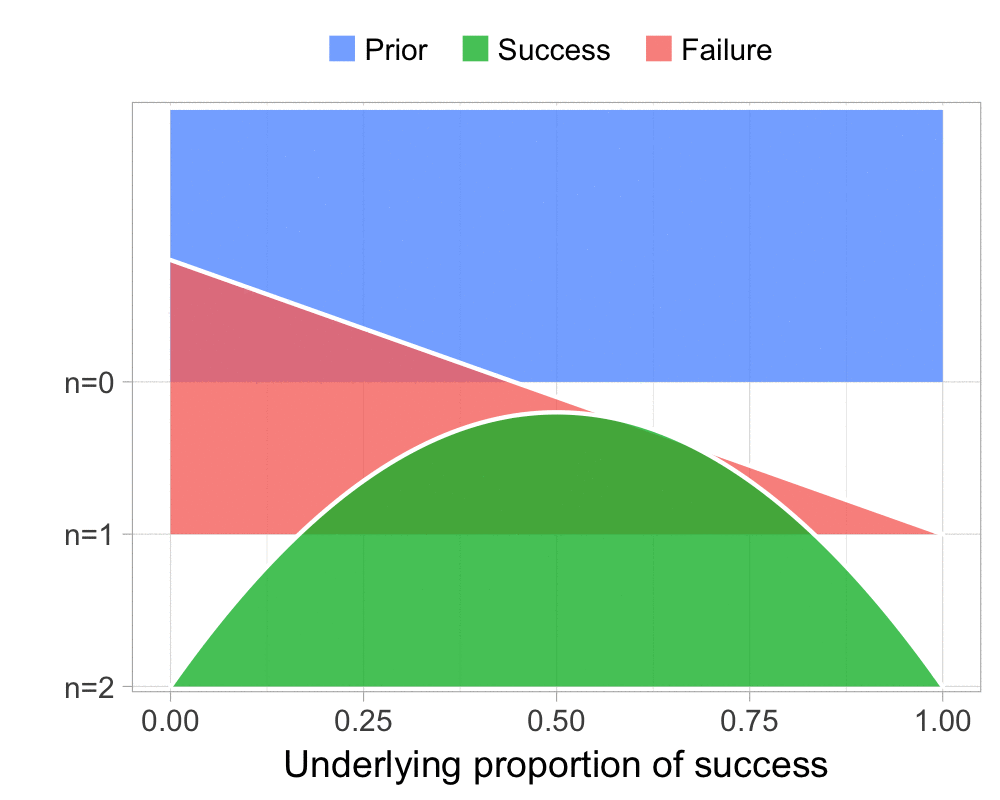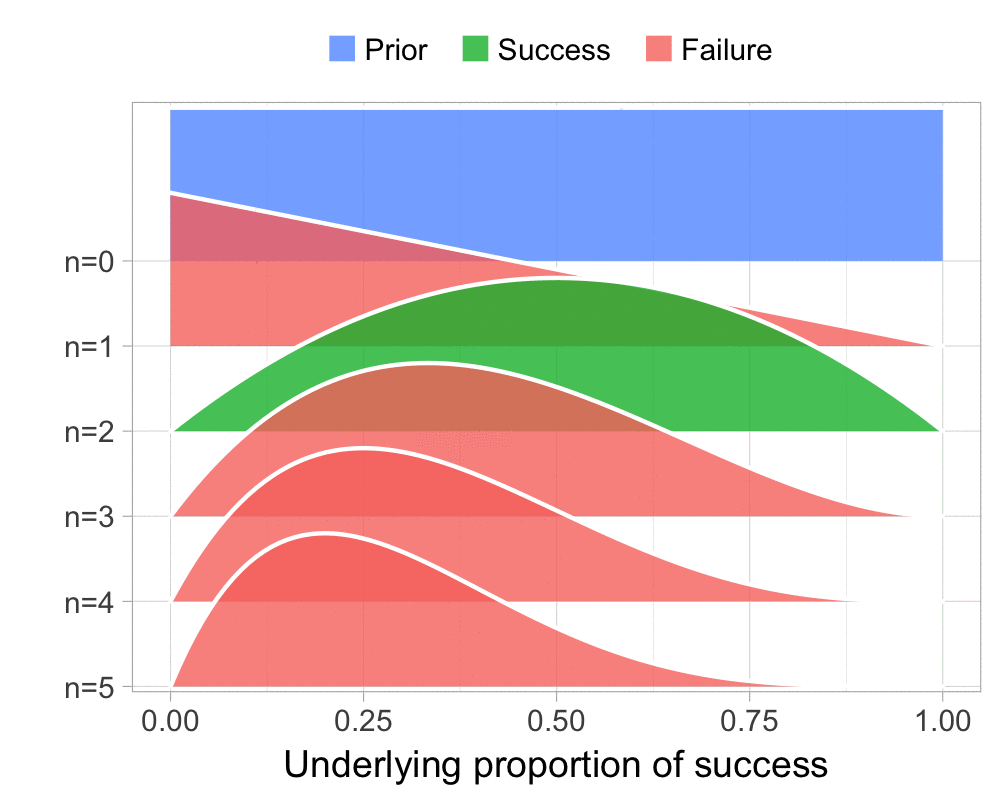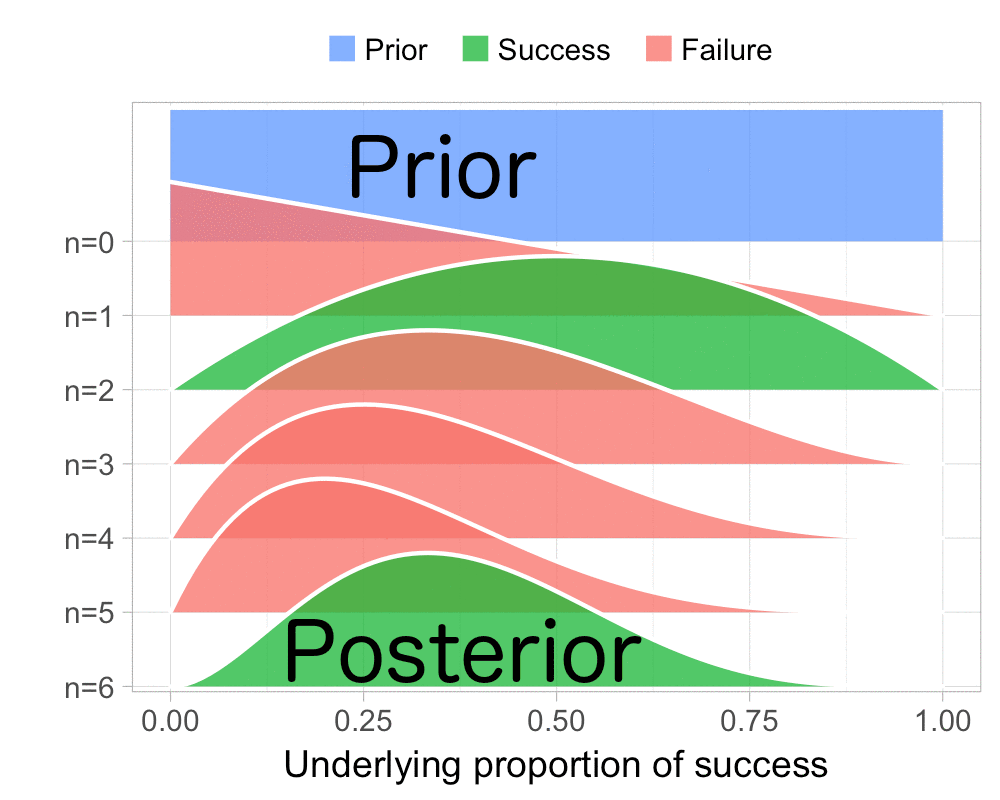
Fundamentals of Bayesian Data Analysis in R and quite a lot of people have asked me for the code I used to visualize the Beta-Binomial. Scroll to the bottom of this post if that’s what you want, otherwise, here is how I visualized the Beta-Binomial in my course given two successes and four failures: