In a previous post I used the the Million Base 2.2 chess data base to calculate the predictive piece values of chess pieces. It worked out pretty well and here, just for fun, I thought I would check out what happens with the predictive piece values over the course of a chess game. In the previous analysis, the data (1,000,000 chess positions) was from all parts of the chess games. Here, instead, are the predictive piece values using only positions up to the 10th first full moves (a full move is when White and Black each have made a move):
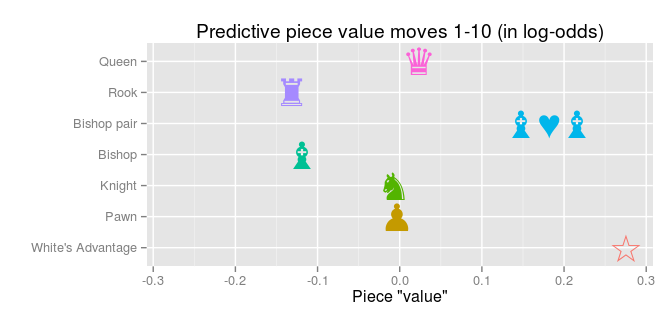
Compared with the predictive piece values using positions from all parts of the chess games the values above are much closer to zero. As the values are given as log-odds (again, see the original post for a brief explanation) this means that the piece balance on the board in the first ten full moves doesn’t predict the outcome of the game very well. This makes sense as how well a player manages the opening of a game isn’t necessarily manifested as a piece advantage until much later in the game. Also, notice that the loss of a rook actually results in a slightly higher probability of winning! This could be due to just a couple of games in the whole data set where one player sacrifices a rook for a positional advantage (as I figure it is pretty rare to lose a rook already during the ten first full moves).
Most of the games in my data set have ended after 60 moves, as this plot shows:
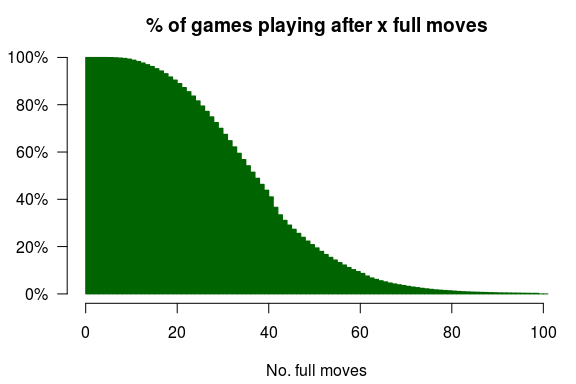
Therefore, I split up the data set into bins of 10 full moves, up to 60 full moves, which resulted in the following predictive piece values:
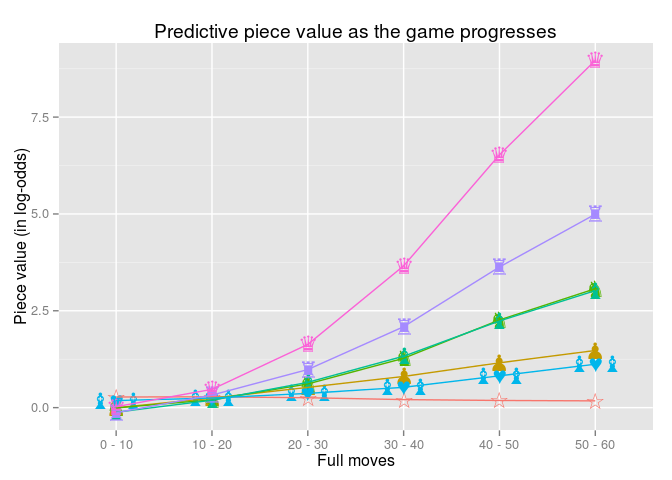
So, as we are getting later into a chess game, the stronger a piece advantage predicts a win. We can also scale the log-odds values so that they are relative to the value of a pawn, with a pawn fixed to 1.0 :
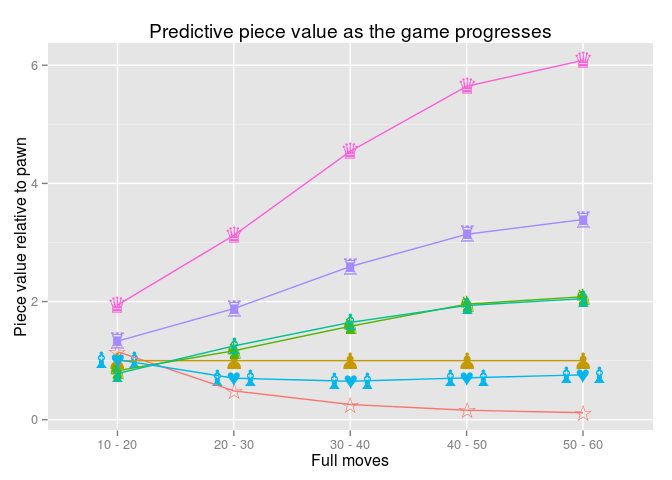
I don’t have much analysis to offer here, except for pointing out the obvious that (1) as before, the later we get into a chess game, the stronger a piece advantage predicts a win, (2) in the late game (full moves 50-60) the predictive piece values almost reach the usual piece values (♟:1, ♞:3, ♝:3, ♜:5, and ♛:9), and (3) that having the advantage of playing White (☆) contributes more to the prediction early in the game, but gets closer to zero later in the game.
If you want to explore the the Million Base 2.2 data base yourself, or want to replicate the analysis above, you’ll find the scripts for doing this in the original Big Data and Chess post.
Update: Some time after publishing this post I received the following interesting e-mail from Marijn Schouten:
The reason I am writing you is to comment on the “mystery regarding the low valuation of all the pieces compared to the pawn” and your assertion that “there is no reason why predictive piece values necessarily should be the same as the original piece values”.
Given the importance of material in chess and the quality of the known values, any plausible outcome would need to approximate those values pretty closely. Otherwise it would necessarily mean that your new values often disagree with conventional wisdom about who is materially ahead.
About the value of the pawn. I think your own analysis shows quite convincingly that actually the pawn is overvalued at almost a knight! Since you did not distinguish between different pawns at all, this is no surprise as some of those pawns will promote and be worth a queen. To correctly value a pawn you will have to take into account its rank (pawn value on 7th rank should be close to a queen), and possibly its file (edge pawns worth less(?), center pawns worth more(?)). None of the other pieces suffer from such a strong dependence on position as the pawn, so your results make perfect sense.